Why virtualize?
• Server consolidation
• Homogenous infrastructure
• Deployment optimizations
• Management optimizations
• Monitoring optimizations
• Hardware utilization
• Reduced Capex
Why not?
• Added complexity
• Additional deployment steps
• Additional management layer
• Additional monitoring layer
• Performance impact
• Workload incompatibility/unsuportability
• Cost of hypervisor
Other considerations:
• Have you already virtualized everything else?
• Exchange 2013 virtualization is fully supported by Microsoft for Server Virtualization Validation Program participating vendors.
• Design for scale-out, not scale-up.
VMware on virtualizing Exchange 2013:
Logical design:
• Determine approach to virtualizing Exchange (how many servers, role placement, clustering, DAGs etc).
• Design Exchange based on number of users and user profile.
• Calculate CPU and memory requirements for all roles.
• Calculate storage requirements for Mailbox server(s).
• Design VM based on Exchange design and vSphere capabilities.
ESXi server architecture:
• Determine VM distribution across the cluster.
• Determine ESXi host specifications (consider scale up vs scale out (licensing), the SPECint_rate2006 benchmark from spec.org).
• Determine initial VM placement.
Supported vSphere features: vMotion DRS, Storage vMotion and vSphere HA.
Supported storage protocols for DAG: FC, iSCSI, FCoE.
CPU:
• Disable HT sharing in VM properties (MS says to disable HT, VMware says to leave it on).
• Number of vCPU =< number of pCPU cores of a NUMA node (for local memory access).
• Use multiple virtual sockets/CPUs and single virtual core in VMware.
• Over-allocating vCPUs can negatively impact performances (high CPU ready and co-stop).
Microsoft on CPU:
- If you have a physical deployment, turn off hyperthreading.
- If you have a virtual deployment, you can enable hyperthreading (best to follow the recommendation of your hypervisor vendor), and:
- Don’t allocate extra virtual CPUs to Exchange server guest VMs.
- Don’t use the extra logical CPUs exposed to the host for sizing/capacity calculations
Exchange 2013 supports a VP:LP ratio of no greater than 2:1, and a ratio of 1:1 is recommended.
When enabled, HT increases CPU throughput slightly (potentially 30%), but it also causes a dramatic increase of base memory utilization (potentially double).
Customers can use processors that support Second Level Address Translation (SLAT) technologies (that is, SLAT-based processors). SLAT technologies add a second level of paging functionality under the paging tables of x86/x64 processors. They provide an indirection layer that maps virtual machine memory addresses to physical memory addresses, which reduces load on the hypervisor for address translation.
SLAT technologies also help to reduce CPU and memory overhead, thereby allowing more virtual machines to be run concurrently on a single Hyper-V machine. The Intel SLAT technology is known as Extended Page Tables (EPT); the AMD SLAT technology is known as Rapid Virtualization Indexing (RVI), formerly Nested Paging Tables (NPT).
Some Intel multicore processors may use Intel Hyper-Threading Technology. When Hyper-Threading Technology is enabled, the actual number of cores that are used by Dynamic Virtual Machine Queue (D-VMQ) should be half the total number of logical processors that are available in the system. This is because D-VMQ spreads the processing across individual physical cores only, and it does not use hyper-threaded sibling cores.
VMware on CPU:
When designing for a virtualized Exchange implementation, sizing should be conducted with physical cores in mind. Although Microsoft supports a maximum virtual CPU to physical CPU overcommitment ratio of 2:1, the recommended practice is to keep this as close to 1:1 as possible.
Virtual machines, including those running Exchange 2013, should be configured with multiple virtual sockets/CPUs. Only use the Cores per Socket option if the guest operating system requires the change to make all vCPUs visible. Virtual machines using vNUMA might benefit from this option, but the recommendation for these virtual machines is generally to use virtual sockets (CPUs in the web client). Exchange 2013 is not a NUMA-aware application, and performance tests have not shown any significant performance improvements by enabling vNUMA.
Memory:
• vRAM =< pRAM of a NUMA node (for local memory access).
• If memory is oversubscribed, reserve the allocated memory (reservation may have negative impact on vMotion).
• The page file size min and max should be set to the operating system’s RAM + 10 MB.
Microsoft on memeory:
Crossing the NUMA boundary can reduce virtual performance by as much as 8 percent. Therefore, configure a virtual machine to use resources from a single NUMA node. For Exchange Server, make sure that allocated memory is equal to or smaller than a NUMA boundary.
By default, a virtual machine gets its preferred NUMA node every time it runs. However, in due course, an imbalance in the assignment of NUMA nodes to the virtual machines may occur. This may happen because each virtual machine has ad hoc memory requirements or because the virtual machines can be started in any order. Therefore, we recommend that you use Perfmon to check the NUMA node preference settings for each running virtual machine. The settings can be checked with the following: \Hyper-V VM Vid Partition (*)\ NumaNodeIndex counter.
Microsoft does not support Dynamic Memory for virtual machines that run any of the Exchange 2013 roles.
VMware on memory:
Do not overcommit memory on ESXi hosts running Exchange workloads. For production systems, it is possible to enforce this policy by setting a memory reservation to the configured size of the virtual machine. Setting memory reservations might limit vSphere vMotion. A virtual machine can only be migrated if the target ESXi host has free physical memory equal to or greater than the size of the reservation.
Non-Uniform Memory Access
In NUMA systems, a processor or set of processor cores have memory that they can access with very little latency. The memory and its associated processor or processor cores are referred to as a NUMA node. Operating systems and applications designed to be NUMA-aware can make decisions as to where a process might run, relative to the NUMA architecture. This allows processes to access memory local to the NUMA node rather than having to traverse an interconnect, incurring additional latency. Exchange 2013 is not NUMA-aware, but ESXi is.
vSphere ESXi provides mechanisms for letting virtual machines take advantage of NUMA. The first mechanism is transparently managed by ESXi while it schedules a virtual machine’s virtual CPUs on NUMA nodes. By attempting to keep all of a virtual machine’s virtual CPUs scheduled on a single NUMA node, memory access can remain local. For this to work effectively, the virtual machine should be sized to fit within a single NUMA node. This placement is not a guarantee because the scheduler migrates a virtual machine between NUMA nodes based on the demand.
The second mechanism for providing virtual machines with NUMA capabilities is vNUMA. When enabled for vNUMA, a virtual machine is presented with the NUMA architecture of the underlying hardware. This allows NUMA-aware operating systems and applications to make intelligent decisions based on the underlying host’s capabilities. vNUMA is enabled for virtual machines with nine or more vCPUs. Because Exchange 2013 is not NUMA aware, enabling vNUMA for an Exchange virtual machine does not provide any additional performance benefit.
Verify that all ESXi hosts have NUMA enabled in the system BIOS. In some systems NUMA is enabled by disabling node interleaving.
Storage:
Block size: 32 KB
DB read/write ratio: 3:2
I/O profile:
DB I/O: 32 KB random
Background DB maintenance: 256 KB sequential read
Log I/O: varies from 4 KB to 1 MB
• Provide at least 30 GB of space on the drive where you will install Exchange.
• Add an additional 500 MB of available disk space for each Unified Messaging (UM) language pack that you plan to install.
• Add 200 MB of available disk space on the system drive.
• Use a hard disk with at least 500 MB of free space to store the message queue database, which can be co-located on the system drive, assuming you have accurately planned for enough space and I/O throughput.
• Use multiple vSCSI adapters/controllers.
• Use eager zeroed thick VMDK or fixed-size VHDX disks.
• Format Windows NTFS volumes for databases and logs with an allocation unit size of 64 KB.
• Follow storage vendor recommendations for path policy.
• Use pre-production tools JetStress and Load Generator to evaluate the storage performance.
Sizing DBs for improved manageability:
• DAG replicated: up to 2 TB (to avoid reseeding issues).
• Non-DAG and not replicated: up to 200 GB (easer management and recovery).
• Consider backup and restore times when calculating the database size.
Microsoft on storage:
Using differencing disks and dynamically expanding disks is not supported in a virtualized Exchange 2013 environment.
Do not use hypervisor snapshots for the virtual machines in an Exchange 2013 production environment.
The virtual IDE controller must be used for booting the virtual machine; however, all other drives should be attached to the virtual SCSI controller. This ensures optimal performance, as well as the greatest flexibility. Each virtual machine has a single virtual SCSI controller by default, but three more can be added while the virtual machine is offline.
VMware on storage:
Verify if there are any benefits in using PVSCSI over LSI SAS.
HBA default queue depth (LSA 32 and PVSCSI 64) can be increased.
Install up to 4 vSCSI adapters and distribute data VMDKs evenly across these adapters.
Compared to VMDK, RDM does not provide significant performance improvements.
Virtual SCSI Adapters
VMware provides two commonly used virtual SCSI adapters for Windows Server 2008 R2 and Windows Server 2012, LSI Logic SAS and VMware Paravirtual SCSI (PVSCSI). The default adapter when creating new virtual machines with either of these two operating systems is LSI Logic SAS, and this adapter can satisfy the requirements of most workloads. The fact that it is the default and requires no additional drivers has made it the default vSCSI adapter for many organizations.
The Paravirtual SCSI adapter is a high-performance vSCSI adapter developed by VMware to provide optimal performance for virtualized business critical applications. The advantage of the PVSCSI adapter is that the added performance is delivered while minimizing the use of hypervisor CPU resources. This leads to less hypervisor overhead required to run storage I/O-intensive applications.
Exchange 2013 has greatly reduced the amount of I/O generated to access mailbox data, however storage latency is still a factor. In environments supporting thousands of users per Mailbox server, PVSCSI might prove beneficial. The decision on whether to use LSI Logic SAS or PVSCSI should be made based on Jetstress testing of the predicted workload using both adapters. Additionally, organizations must consider any management overhead an implementation of PVSCSI might introduce. Because many organizations have standardized on LSI Logic SAS, if the latency and throughput difference is negligible with the proposed configuration, the best option might be the one with the least impact to the current environment.
Virtual machines can be deployed with up to four virtual SCSI adapters. Each vSCSI adapter can accommodate up to 15 storage devices for a total of 60 storage devices per virtual machine. During allocation of storage devices, each device is assigned to a vSCSI adapter in sequential order. Not until a vSCSI adapter reaches its 15th device will a new vSCSI adapter be created. To provide better parallelism of storage I/O, equally distribute storage devices among the four available vSCSI adapters.
EMC on storage:
Both Thick and Thin LUNs can be used for Exchange storage (database and logs). Thick LUNs are recommended for heavy workloads with high IOPS user profiles. Thin LUNs are recommended for light to medium workloads with low IOPS user profiles.
Format Windows NTFS volumes for databases and logs with an allocation unit size of 64 KB.
Network:
• Use VMXNET3 or synthetic vNIC adapter.
• Turn on RSS for vNICs in Device Manager.
• Allocate at least 2 pNICs to Exchange.
Microsoft on network:
Synthetic adapters are the preferred option for most virtual machine configurations because they use a dedicated VMBus to communicate between the virtual NIC and the physical NIC. This results in reduced CPU cycles, as well as much lower hypervisor/guest transitions per operation. The driver for the synthetic adapter is included with the Integration Services that are installed with the Windows Server 2012 guest operating system. At minimum, customers should use the default synthetic vNIC to drive higher levels of performance. In addition, should the physical network card support them, the administrator should take advantage of a number of the NIC offloads that can further increase performance.
Single Root I/O Virtualization (SR-IOV) can provide the highest levels of networking performance for virtualized Exchange virtual machines. Check with your hardware vendor for support because there may be a BIOS and firmware update required to enable SR-IOV.
VMware on network:
For Exchange 2013 virtual machines participating in a database availability group (DAG), configure at least two virtual network interfaces, connected to different VLANs or networks. These interfaces provide access for Messaging Application Programming Interface (MAPI) and replication traffic.
Although Exchange 2013 DAG members can be deployed with a single network interface for both MAPI and replication traffic, Microsoft recommends using separate network interfaces for each traffic type. The use of at least two network interfaces allows DAG members to distinguish between system and network failures.
If Exchange servers using VMXNET3 experience packet loss during high-volume DAG replications, gradually increase the number of buffers in the guest operating system - follow VMware KBA 2039495.
Performances:
• Select the high performance power plan in Windows.
• Use affinity/antiaffinity rules (keep the in line servers e.g. CAS1 and MBX1 on the same host to avoid network traffic between these, and keep DAG members and/or multiple CAS servers on different hosts for high-availability).
• Set power policy to high-performance in vSphere.
VMware Performance Counters for Exchange

Storage performance monitoring:

RPC average latency:
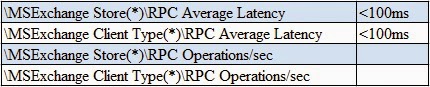
Watch for high query latencies on Exchange servers and high CPU utilization on Active Directory:
Allocate sufficient amount of RAM to AD so it can cache the entire database file.
For large deployments, research the issues related to NTLM auth and MaxConcurrentAPI.
Other recommendations:
Microsoft:
For an Exchange 2013 virtual machine, do not configure the virtual machine to save state. We recommend that you configure the virtual machine to use a shut down because it minimizes the chance that the virtual machine can be corrupted. When a shut down happens, all jobs that are running can finish, and there will be no synchronization issues when the virtual machine restarts (for example, a Mailbox role server within a DAG replicating to another DAG member).
Use the Failover Priority setting to ensure that, upon failover, the Exchange 2013 virtual machines start in advance of other, less important virtual machines. You can set the Failover Priority setting for the Exchange 2013 virtual machine to high. This ensures that even under contention, the Exchange 2013 virtual machine, upon failover, will successfully start and receive the resources it needs to perform at the desired levels—taking resources from other currently running virtual machines, if required.
When performing live migration of DAG members, follow these key points:
• If the server offline time exceeds five seconds, the DAG node will be evicted from the cluster. Ensure that the hypervisor and host-based clustering use the Live Migration technology in Hyper-V to help migrate resources with no perceived downtime.
• If you are raising the heartbeat timeout threshold, perform testing to ensure that migration succeeds within the configured timeout period.
• On the Live Migration network, enable jumbo frames on the network interface for each host. In addition, verify that the switch handling network traffic is configured to support jumbo frames.
• Deploy as much bandwidth as possible for the Live Migration network to ensure that the live migration completes as quickly as possible.
VMware:
Allowing two nodes from the same DAG to run on the same ESXi host for an extended period is not recommended when using symmetrical mailbox database distribution. DRS anti-affinity rules can be used to mitigate the risk of running active and passive mailbox databases on the same ESXi host.
During a vSphere vMotion operation, memory pages are copied from the source ESXi host to the destination. These pages are copied while the virtual machine is running. During the transition of the virtual machine from running on the source to the destination host, a very slight disruption in network connectivity might occur, typically characterized by a single dropped ping. In most cases this is not a concern, however in highly active environments, this disruption might be enough to trigger the cluster to evict the DAG node temporarily, causing database failover. To mitigate cluster node eviction, the cluster heartbeat interval can be adjusted.
The Windows Failover Cluster parameter samesubnetdelay can be modified to help mitigate database failovers during vSphere vMotion of DAG members. This parameter controls how often cluster heartbeat communication is transmitted. The default interval is 1000ms (1 second). The default threshold for missed packets is 5, after which the cluster service determines that the node has failed. Testing has shown that by increasing the transmission interval to 2000ms (2 seconds) and keeping the threshold at 5 intervals, vSphere vMotion migrations can be performed with reduced occurrences of database failover.
Microsoft recommends using a maximum value of 10 seconds for the cluster heartbeat timeout. In this configuration the maximum recommended value is used by configuring a heartbeat interval of 2 seconds (2000 milliseconds) and a threshold of 5 (default).
Database failover due to vSphere vMotion operations can be mitigated by using multiple dedicated vSphere vMotion network interfaces. In most cases, the interfaces that are used for vSphere vMotion are also used for management traffic. Because management traffic is relatively light, this does not add significant overhead.
Using jumbo frames reduces the processing overhead to provide the best possible performance by reducing the number of frames that must be generated and transmitted by the system. During testing, VMware had an opportunity to test vSphere vMotion migration of DAG nodes with and without jumbo frames enabled. Results showed that with jumbo frames enabled for all VMkernel ports and on the VMware vNetwork Distributed Switch, vSphere vMotion migrations of DAG member virtual machines completed successfully. During these migrations, no database failovers occurred, and there was no need to modify the cluster heartbeat setting.
Ask The Perf Guy: What’s The Story With Hyperthreading and Virtualization?
Best Practices for Virtualizing & Managing Exchange 2013
Large packet loss at the guest OS level on the VMXNET3 vNIC in ESXi 5.x / 4.x.
Microsoft Clustering on VMware vSphere: Guidelines for supported configurations
Microsoft Exchange Server (2010 & 2013) Best Practices and Design Guidelines for EMC Storage 1
Microsoft Exchange Server (2010 & 2013) Best Practices and Design Guidelines for EMC Storage 2
Microsoft Exchange 2013 on VMware Availability and Recovery Options
Microsoft Exchange 2013 on VMware Best Practices Guide
Microsoft Exchange 2013 on VMware Design and Sizing Guide
Microsoft Exchange Server 2013 Sizing
Monitoring and Tuning Microsoft Exchange Server 2013 Performance
Poor network performance or high network latency on Windows virtual machines
Processor Query Tool
The Standard Performance Evaluation Corporation
Virtual Receive-side Scaling in Windows Server 2012 R2
Virtualization in Microsoft Exchange Server 2013
VMWorld 2013: Successfully Virtualize Microsoft Exchange Server
.